I wrote this post for ‘non-geek’ people/teams. The following data can be extracted also using Twitter API etc. Not every team/organization is lucky enough to have great developers on board and sometimes there’s no time to find/outsource/hire some. So my aim was to give the possibility to ‘average’ managers to get relevant data to use in their analysis by using free and easy to use tools. Your contributions are more than welcome so if you want to share in the comments how to do it with API, other scripts etc. go ahead! In this post I’ll keep it simple for everyone.
The Twitter Lists feature is a way to organize the people, brands or whoever else you are following on twitter. What’s interesting about Twitter Lists is that they represent something more than a simple tool to organize contacts. In Twitter Lists we can find a huge amount of data that can be analyzed to understand how people identify with a specific brand.
How can we analyze this data? We could do this in several different ways using the Twitter API etc. but keeping in mind that probably not everybody has professional web development skills in this post I’ll show you how you can do this by simply using:
- free/open-source tools/software
- some utilities on your Mac (if you are a PC user, go ahead and share in the comments similar tools that can be used on PCs!)
So no problem, you’ll be able to complete this tutorial without specific programming skills 🙂 .
In this post I’ll use as an example BlackBerry (RIM), a brand that I follow and that I’m interested in. If you don’t have/know which brand to analyze, try with your own twitter account and analyze your ‘personal brand’!
Don’t get scared by the length of this post. The process to extract data for our analysis is quite fast. This post is really detailled to simply help you and make it faster 😉
Time required
- To complete this tutorial: Between 15 and 30 min. It depends about the level of confidence you have with the listed tools and about the number of lists you have to process.
- To repeat and perform again this process after the tutorial: For me it took 15 min. to process 1446 Twitter Lists. You can get it done faster with less lists.
Before starting:
1) Download and install Skim. It’s free and you can get it here http://skim-app.sourceforge.net.
Skim is a PDF viewer. It’s scriptable and it also features an AppleScript command to extract the text from certain PDF pages, that’s why we need it.
2) Open AppleScript Editor (you’ll find it in Applications > Utilities > AppleScript Editor)
![]()
With AppleScript, we can write a script (which is essentially a set of instructions) to perform tasks within the existing applications on your Mac or within the operating system itself.
Once you opened AppleScript choose from the top menu ‘Window’ and then 1) Click on ‘Library’ 2) Make sure Skim is on the list. If Skim is not on the list you may need to add it by clicking the ‘+’ button
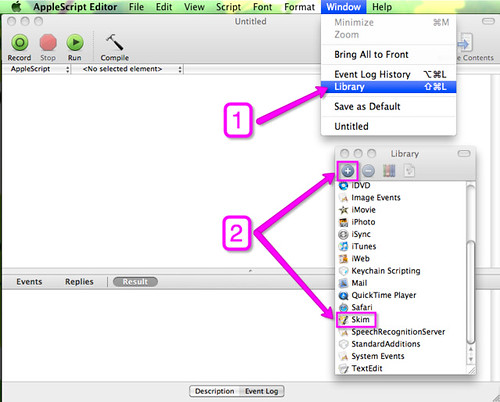
Ok now we can start so…here we go:
Extract the data from Twitter
Visit the twitter account of the brand you want to analyze. I’m my case http://twitter.com/BlackBerry (but it could be http://twitter.com/vascellari if I wanted to analyze my ‘personal brand’). Go to the Lists that are following your brand.
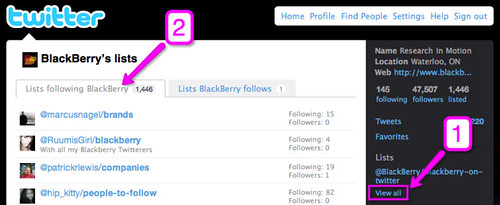
1) Click on ‘View all’ on you sidebar (under Lists)
2) Click on ‘Lists following YOUR BRAND’ You should get to a page similar to the one on the screen-shot below. In my case is http://twitter.com/BlackBerry/lists/memberships
click to enlarge the screen-shots
Extract the data from the page by selecting and copying all the lists on the page.

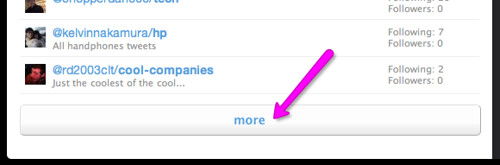
Remember: If the brand you are analyzing is followed by a big number of lists (like in my case), before selecting and copying (as mentioned above) you might want to click on the ‘More’ button at the bottom of the page. Keep clicking till when the page will display the entire/desired number of lists. I this example I analyze 1446 lists (72 clicks to display them all. No worries, you can do that in a couple of minutes 😉 ).
Reorder the data
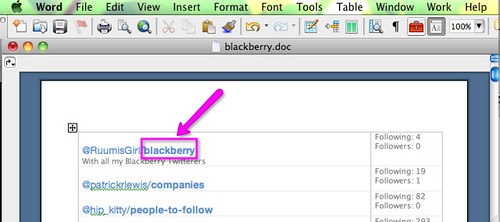
You can do this by pasting the data you copied from the twitter page on a Microsoft Word or a TextEdit document (TextEdit is a free text editor software that comes with your Mac. PCs have similar tools too). Important: make sure you maintain the blod fonts when you paste!
Save the document as a PDF. On Macs you can do this by selecting form the top menu ‘File’ > ‘Print’ > and then ‘Save as PDF’
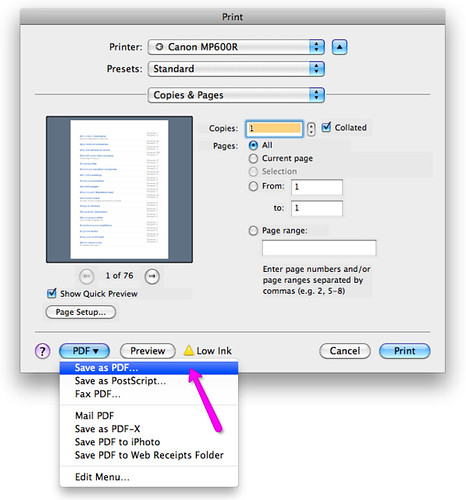
Extract the lists
So now we have a PDF file that contains all the data we got from the Twitter Lists. Good but certainly not enough. What we want to do next is to extract from that PDF only the name of the lists. That’s what’s relevant for our analysis. Why? Because the name of the lists are a good and direct indicator of how people identify with our brand.
You probably noticed that the name of each list is blod. What we are going to do now is extracting the blod text from our PDF file.
- Open with Skim (Skim: remember the application you installed at the beginning of this tutorial? 🙂 ) the PDF file that contains our twitter lists data (Then leave Skim open and move to the next point).
- Open AppleScript Editor (you’ll find it in Applications > Utilities > AppleScript Editor)
![]()
Then
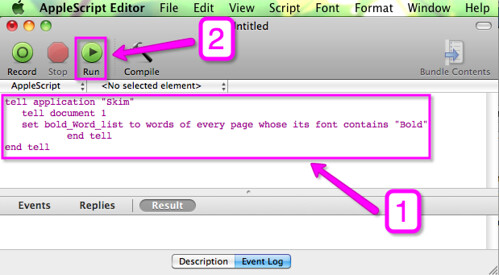
1) Copy the following script that I already prepared for you and paste it into the AppleScript Editor.
2) Click on the ‘run’ button (check screen-shot below)
script:
tell application "Skim" tell document 1 set bold_Word_list to words of every page whose its font contains "Bold" end tell end tell
Select and copy the results

Save your script so you’ll be able to use it again in future. It will show up among your applications in your Mac.
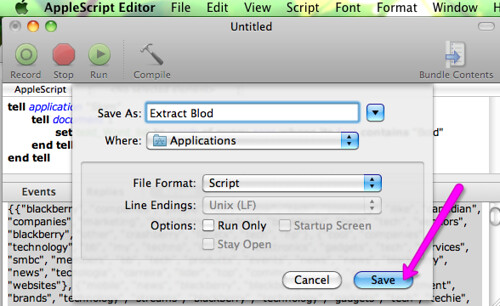
Process the extracted Lists
Ok now that we have a massive cloud of data, we need process it and make it easier to read and analyze. Also in this case we could use several different tools to process it but to keep it easy and simple I’ll use wordle.net
Wordle is a tool for generating “word clouds” from text that you provide. The clouds give greater prominence to words that appear more frequently in the source text.
If you want a more detailed statistical analysis like the frequency of individual words, number of unique words, average number of words, etc. you can use any text content analyzer. Here’s a free one.
Indeed, if you are a wizard of Visual Basic or a master of Marcos… please go ahead and share your tips in the comments or on your blog! Just don’t forget to link back to this post or letting me know about it 🙂 Other people might find it useful!).
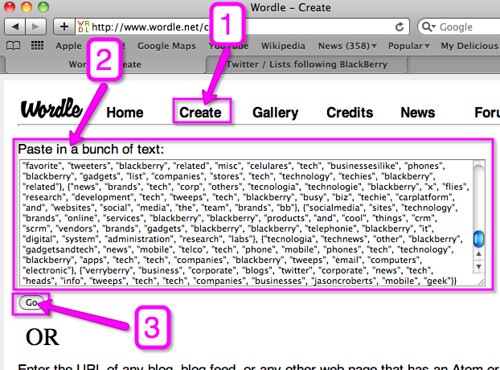
So now visit Wordle.net and…
1) Click on ‘create’
2) Paste the results we copied from AppleScript
3) Click on ‘Go’
Tadaaan…Look at our cloud (below). definitely more digestible, isn’t it?! 🙂
click on the pict to view it in full size (9000 x 6500 pixels)

Re-pitch (optional)
This tutorial guide would end here if you processed just few hundreds keywords but in my case I had 1446 lists to take care of so the result I got is good but I definitely have to pitch it more to get the best out of it. The main problem, that I’m sure many of you already spotted, is that probably lots of people saved BlackBerry’s twitter account in their lists as ‘BlackBerry’…hehh well I agree this is not surprising, but we have to deal with it.
– The good side of it: We understand that lost of people identify with BlackBerry. This is positive. If the most prominent keyword in our cloud was ‘Phones’ or some other general one, this would probably mean that people see BlackBerry as simply one of the many devices they can get.
– The bad side of it: The size of the results tagged as ‘BlackBerry’ is quite big so it doesn’t let us understand how the rest of the people identify, how do they see or what do they feel for this brand. Taking into exame such a big number of tags of a well know brand like BlackBerry (RIM) can lead to problems like this, processing lists related to your ‘personal brand’ would probably give us a different end result. So…
How to get rid of most prominent/obvious results? (Like in my case ‘BlackBerry’)
It’s simple. Repeat the previous steps but before creating the PDF find the most prominent list/data you want to exclude and replace it with a number. (To find a specific keyword in your text editor on Mac, click CMD+F or from the menu ‘Edit’>’Find’).
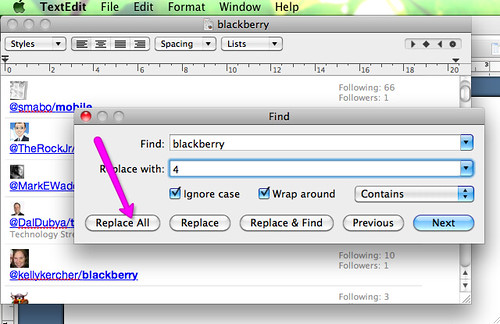
Then when you process the data in Wordle make sure to ‘Remove numbers’ (you find this option on the menu on top of your tag cloud, under ‘Language’)
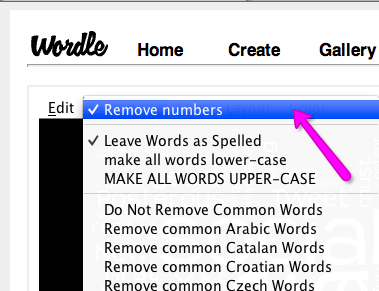
The result is much different than the previous one. You can see that other elements start to emerge from our cloud giving us more inputs to analyze.
click on the pict to view it in full size (9000 x 6500 pixels)

Analyze
At this point you just have to analyze your results. I’m sure you’ll find something interesting in your analysis. I certainly didn’t know people could identify and tag BlackBerry with ‘shopping’! 😉

Remember: Again, I used BlackBerry as an example and I certainly didn’t go deep into analyzing our results. Every communicator knows that the real work starts from this point on. Analysis change from brand to brand and most importantly are usually related to your strategic communications plan.
I hope you found this post interesting and I hope it will help you and your teams in doing a better job by having an ‘active’ social media approach rather then a ‘passive’ use.
All this is nothing without a plan! Please keep it in mind.
The focus of this post is more at tactical level. Don’t forget your strategy. Your analysis must support, focus and be related to your overall strategy. If you have no idea of what I’m talking about I suggest you to have a look at a couple of other posts I wrote and that you might find interesting:
Communications Planning Guide: A step by step road map that will help in crafting your plans at strategic and tactical level.
Communications Plan: Strategy & Tactics: Helps you in understanding the difference between strategy and tactics. Way to many people still confuse or mix the two.
7 New Marketing Tips for your Organization: What new marketing does and why it works. List of basic tips that you can take into action in your business/organization.
What would would you add to this guide? Share your experience, suggestions and tips! As usual via Twitter (@vascellari), Friendfeed, or other channels too, just remember to link back to this post!
Andrea